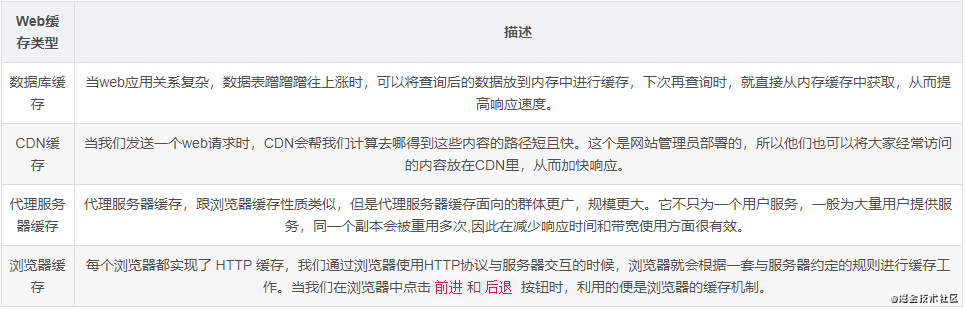
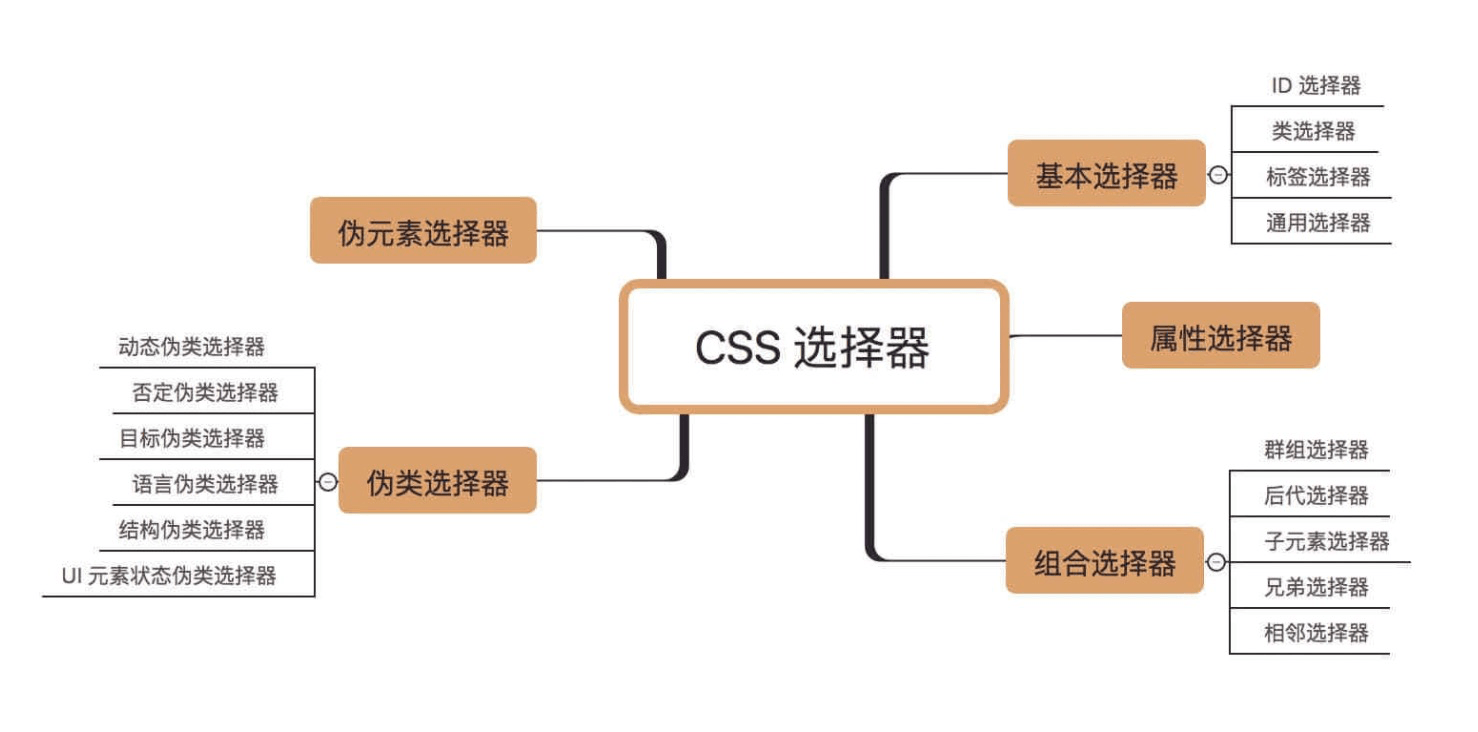
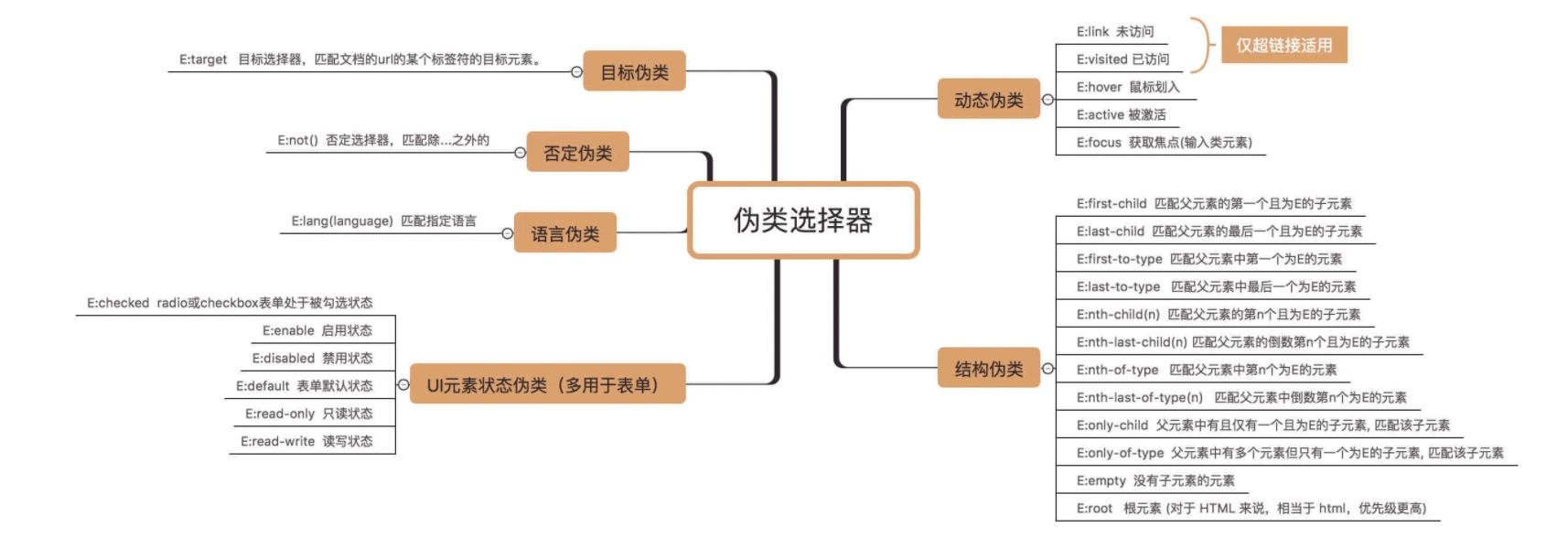
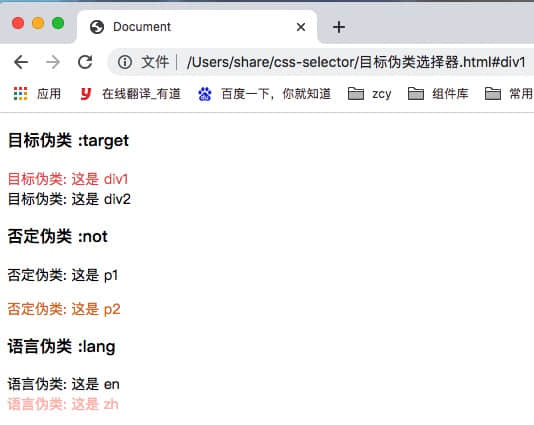
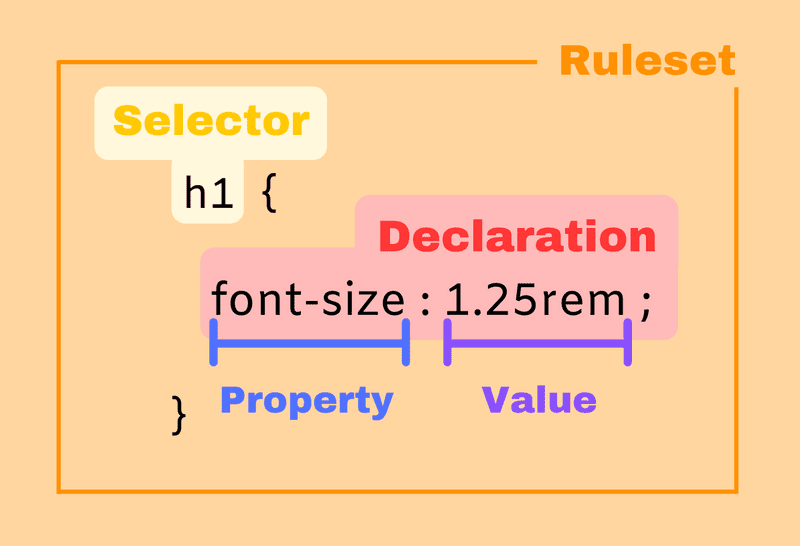
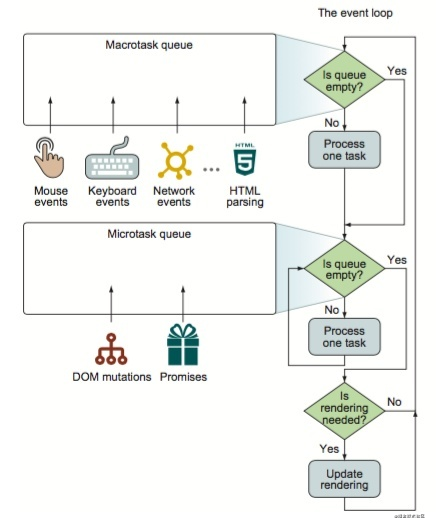
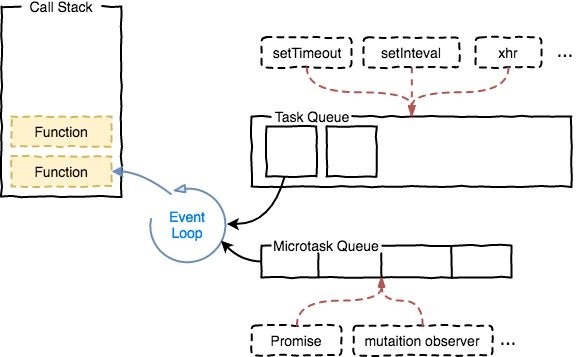
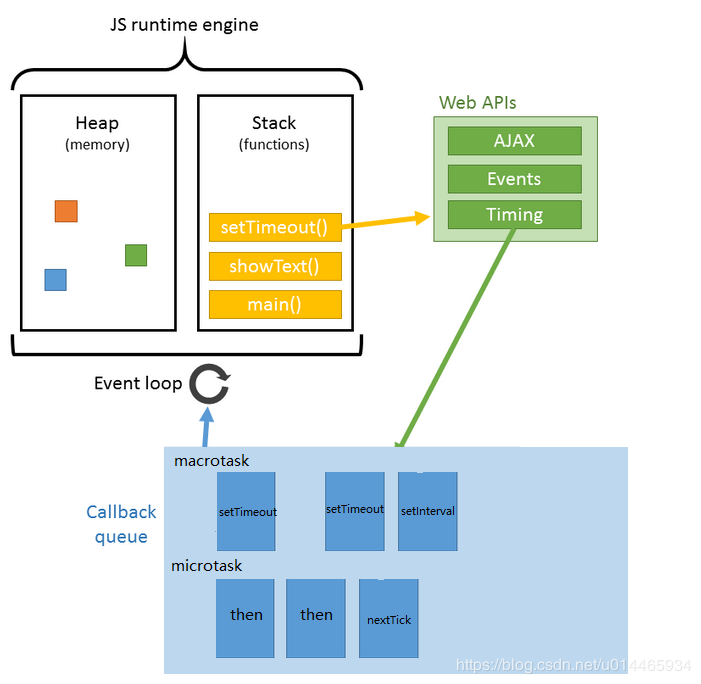
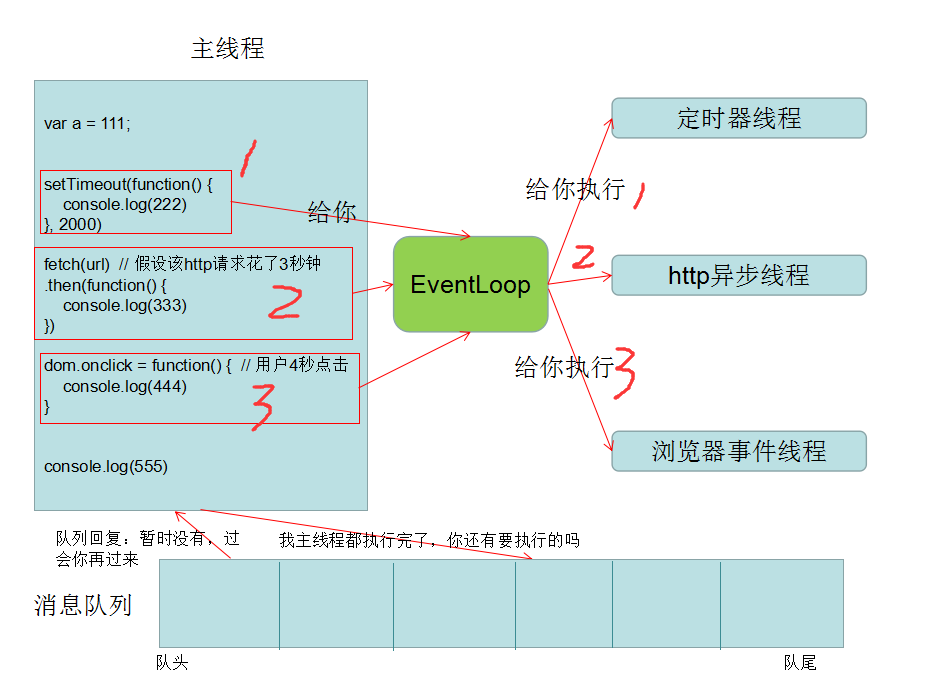
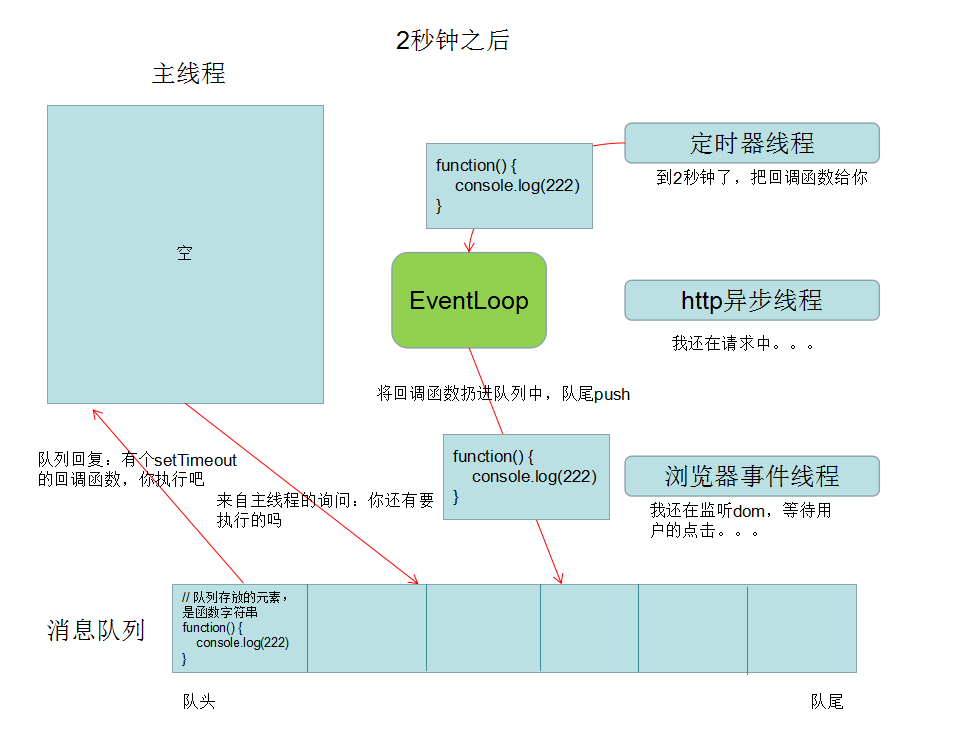
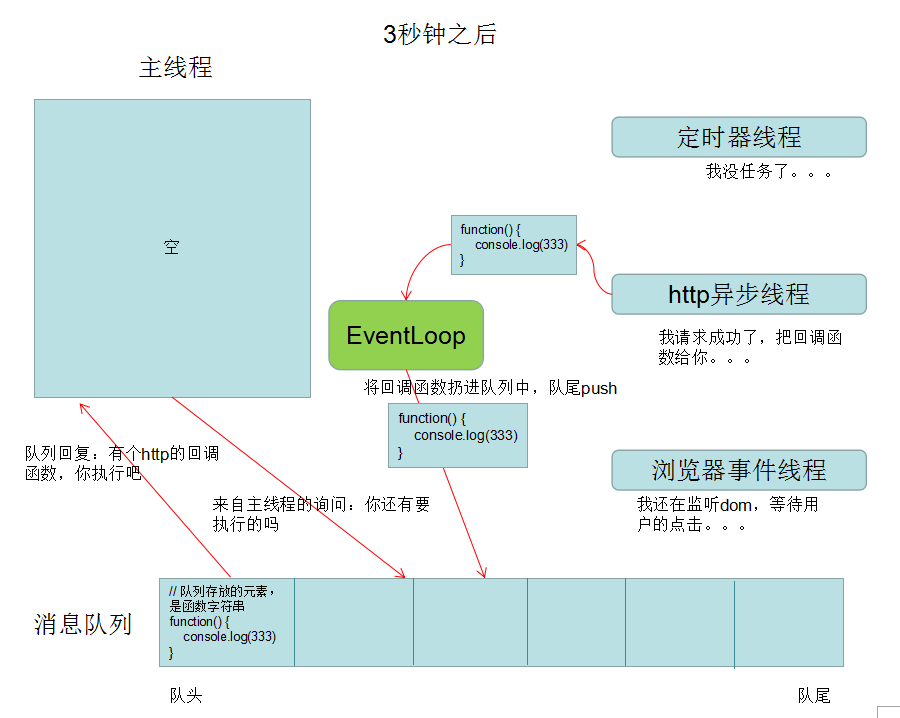
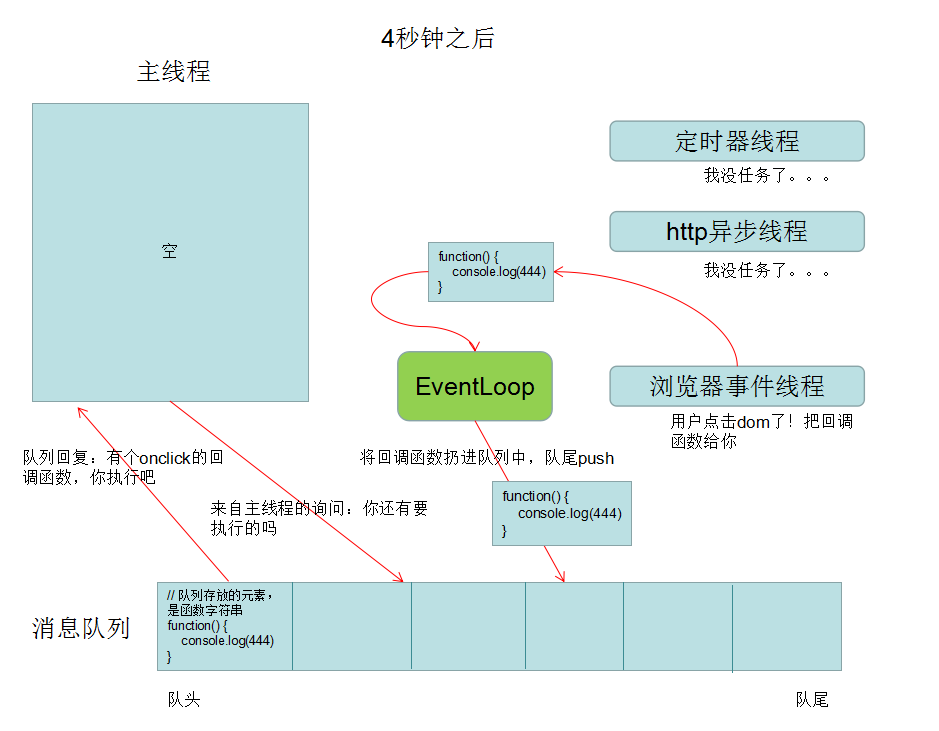
语法 CSS的核心功能是将CSS属性设置为特定的值。一个属性与值的键值对称为声明。
将声明用{}包起来后,就组成了声明块。
1 2 3 4 { color : red; text-align : center; }
选择器和声明块组成了CSS规则集,常常简称CSS规则。
1 2 3 4 span { color : red; text-align : center; }
CSS注释:
@规则 CSS包含的@规则:
@namespace告诉CSS引擎必须考虑XML命名空间
@media如果满足媒体查询条件则条件规则组里的规则生效
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @media screen and (min-width : 900px ) { article { padding : 1rem 3rem ; } } @supports (display : flex) { @media screen and (min-width : 900px ) { article { display : flex; } } }
@page描述打印文档时布局的变化
1 2 3 4 5 6 7 @page { margin : 1cm ; } @page :first { margin : 2cm ; }
@font-face描述将下载的外部字体
@keyframes描述CSS动画的关键帧
1 2 3 4 5 6 7 8 9 @keyframes slidein { from { transform : translateX (0% ); } to { transform : translateX (100% ); } }
@document文档样式表满足给定条件则条件规则组里的样式生效
@charset用于定义样式表使用的字符集,它必须是样式表的第一个元素。如果有多个@charset被声明,只有第一个被使用。
样式表用什么编码,浏览器的识别程序:
文件开头的 Byte order mark 字符值,不过⼀般编辑器并不能看到文件头里的 BOM 值;
HTTP 响应头里的 content-type 字段包含的 charset 所指定的值,比如:
1 Content -Type: text/css; charset=utf-8
CSS文件头里定义的@charset规则里指定的字符编码
默认是UTF-8
@import告诉CSS引擎引入一个外部样式表
link和@import都能导入样式文件,有什么区别:
link 是 HTML 标签,除了能导入CSS 外,还能导入别的资源,比如图片、脚本和字体等;而@import 是 CSS 的语法,只能用来导入CSS;
link 导入的样式会在页面加载时同时加载,@import 导入的样式需等页面加载完成后再加载;
link没有兼容问题,@import不兼容ie5以及以下;
link 可以通过 JS 操作 DOM 动态引入样式表改变样式,而@import不可以。
@support用于查询特定的CSS是否生效,可以结合not、and和or操作符决定后续的操作。
1 2 3 4 5 6 7 8 9 10 11 @supports (display : grid ) { div { display : grid; } } @supports not (display : grid ) { div { float : right; } }
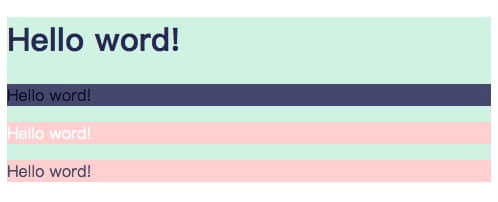
层叠性 越往下优先级越高:
用户代理样式表中的声明(浏览器的默认样式,没有设置其他样式时使用)
作者样式表中的常规声明(开发人员设置的样式)
作者样式表中的!important声明
针对同一个选择器,定义在后面的声明会覆盖前面的;作者定义的样式会比默认继承的样式优先级更高。
选择器 基础选择器 标签选择器:h1
类选择器:.checked
ID选择器:#picker
通配选择器:*
属性选择器 [attr] :指定属性的元素;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 a [title] { color : purple; } a [href="https://example.org" ] { color : green; } a [href*="example" ] { font-size : 2em ; } a [href$=".org" ] { font-style : italic; } a [class~="logo" ] { padding : 2px ; }
组合选择器 相邻兄弟选择器: A + B
伪类 条件伪类 :lang() :基于元素语言来匹配页面元素;
行为伪类 :active :鼠标激活的元素;
状态伪类 :target :当前锚点的元素;
结构伪类 :root :文档的根元素;
伪元素 ::before :在元素前插入内容;
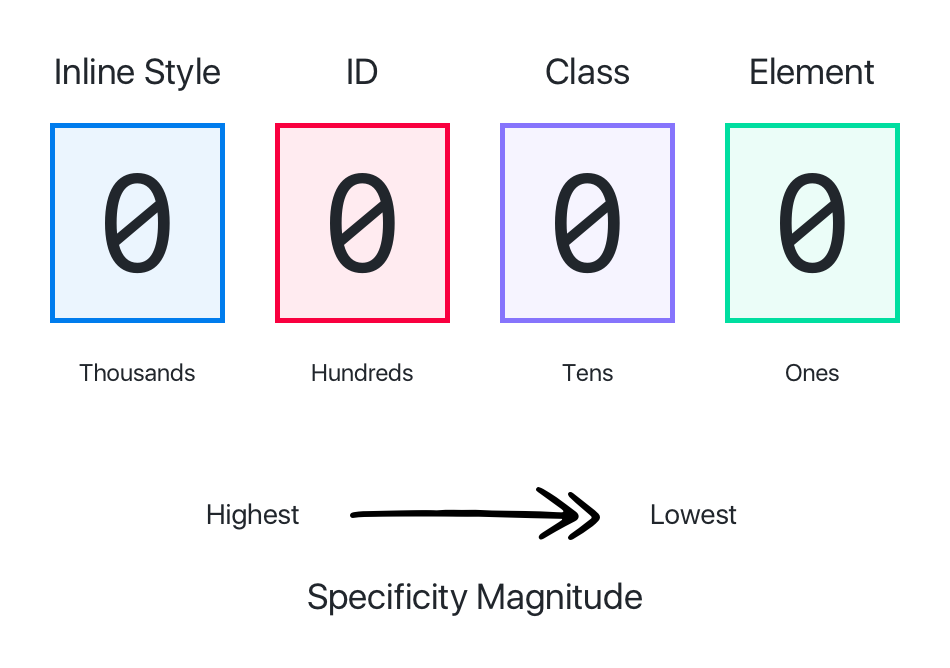
优先级
权重分成如下几个等级,数值越大权重越高:
10000:!important;
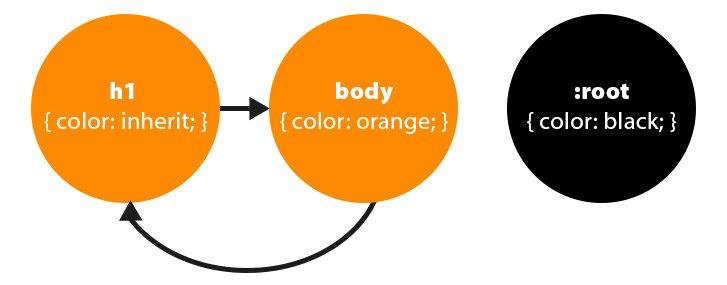
继承性 在 CSS 中有一个很重要的特性就是子元素会继承父元素对应属性计算后的值。比如页面根元素html 的文本颜色默认是黑色的,页面中的所有其他元素都将继承这个颜色,当申明了如下样式后,H1 文本将变成橙色。
1 2 3 4 5 6 body {color : orange;} h1 {color : inherit;}
存在默认继承的是那些不会影响到页面布局的属性,如下:
字体相关: font-family 、font-style 、font-size 、font-weight 等;
对于其他默认不继承的属性也可以通过以下几个属性值来控制继承行为:
inherit :继承父元素对应属性的计算值;
文档流 在 CSS 的世界中,会把内容按照从左到右、从上到下的顺序进行排列显示。正常情况下会把页面分割成一行一行的显示,而每行又可能由多列组成,所以从视觉上看起来就是从上到下从左到右,而这就是 CSS 中的流式布局,又叫文档流。文档流就像水⼀样,能够自适应所在的容器,一般它有如下几个特性:
如何脱离文档流 脱流文档流指节点脱流正常文档流后,在正常文档流中的其他节点将忽略该节点并填补其原先空间。文档⼀旦脱流,计算其父节点高度时不会将其高度纳入,脱流节点不占据空间。有两种方式可以让元素脱离文档流:浮动和定位。
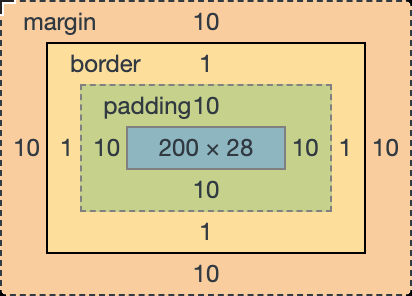
盒模型 在 CSS 中任何元素都可以看成是⼀个盒子,而⼀个盒子是由 4 部分组成的:内容(content)、内边距(padding)、边框(border)和外边距(margin)。
盒模型有两种:标准盒模型和IE盒模型。
1 2 3 4 5 6 7 .box { width : 200px ; height : 200px ; padding : 10px ; border : 1px solid #eee ; margin : 10px ; }
标准盒模型认为:盒子的实际尺寸 = 内容(设置的宽/高) + 内边距 + 边框
所以 .box 元素内容的宽度就为 200px ,而实际的宽度则是 width + padding-left + padding-right + border-left-width + border-right-width = 200 + 10 + 10 + 1 + 1 = 222。
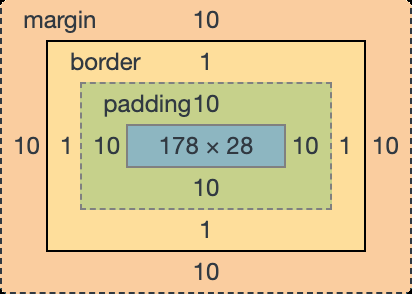
IE 盒模型认为:盒子的实际尺寸 = 设置的宽/高 = 内容 + 内边距 + 边框
.box 元素所占用的实际宽度为 200px ,而内容的真实宽度则是 width - padding-left -padding-right - border-left-width - border-right-width = 200 - 10 - 10 - 1 - 1 = 178。
高版本的浏览器默认使用标准盒模型。
CSS3中新增了一个属性box-sizing,指定盒子使用什么标准:
content-box :标准盒模型;
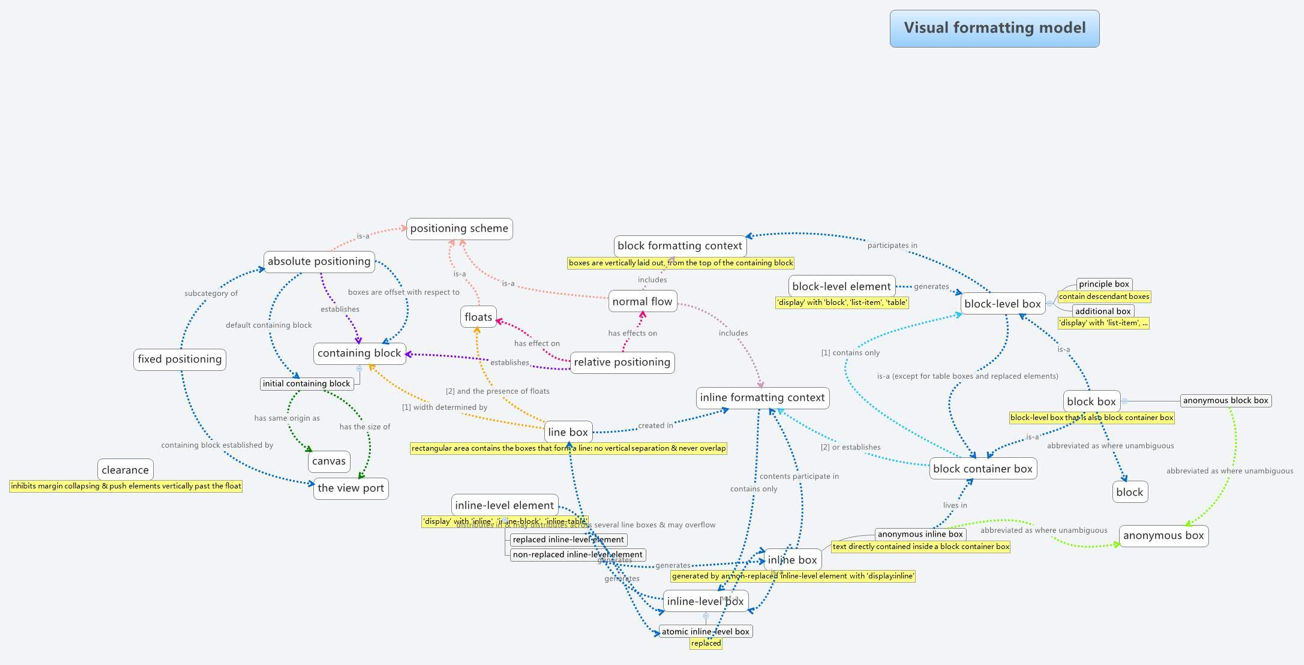
视觉格式化模型 视觉格式化模型(Visual formatting model)是用来处理和在视觉媒体上显示文档时使用的计算规则。CSS 中一切皆盒子,而视觉格式化模型简单来理解就是规定这些盒子应该怎么样放置到页面中去,这个模型在计算的时候会依赖到很多的因素,比如:盒子尺寸、盒子类型、定位方案(是浮动还是定位)、兄弟元素或者子元素以及一些别的因素。
盒子类型由 display 决定,同时给⼀个元素设置 display 后,将会决定这个盒子的 2 个显示类型(display type):
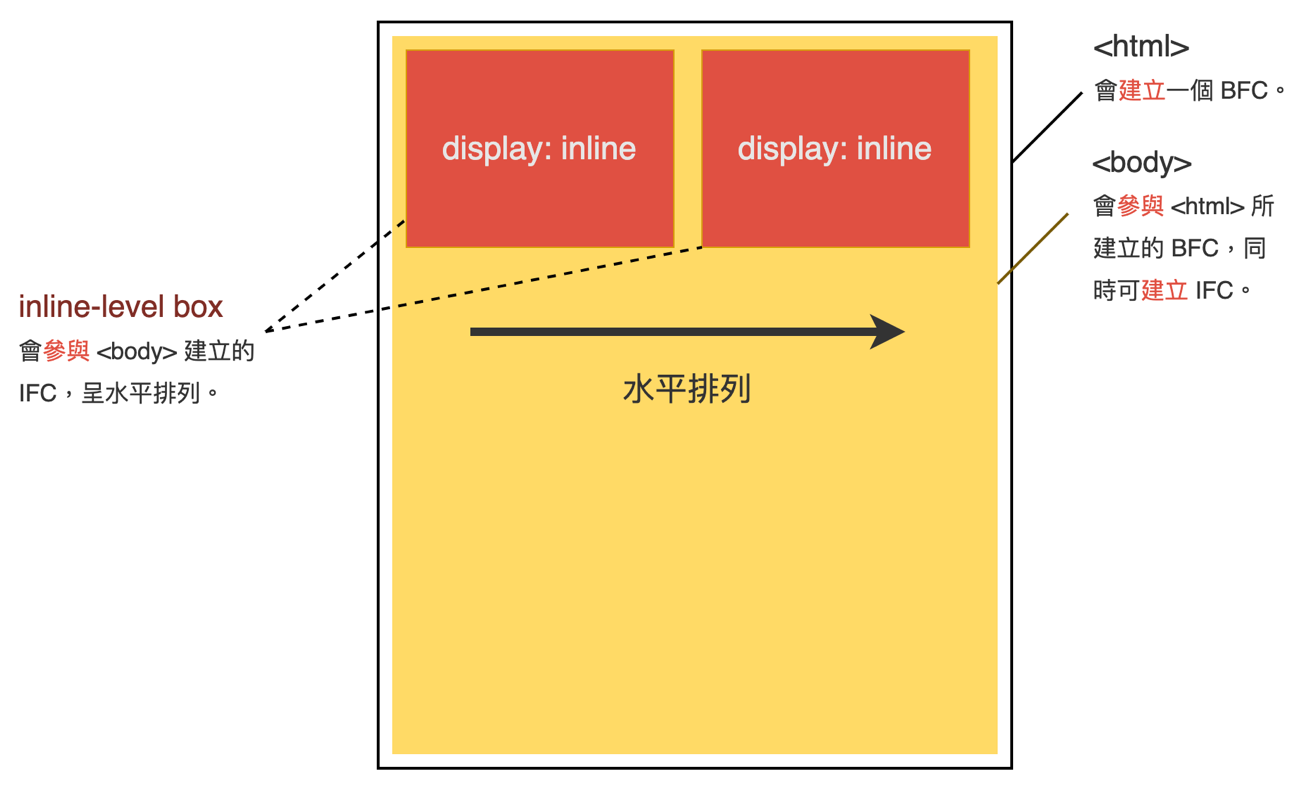
outer display type 对外显示方面,盒子类型可以分成 2 类:block-level box(块级盒子) 和 inline-level box(行内级盒子)。
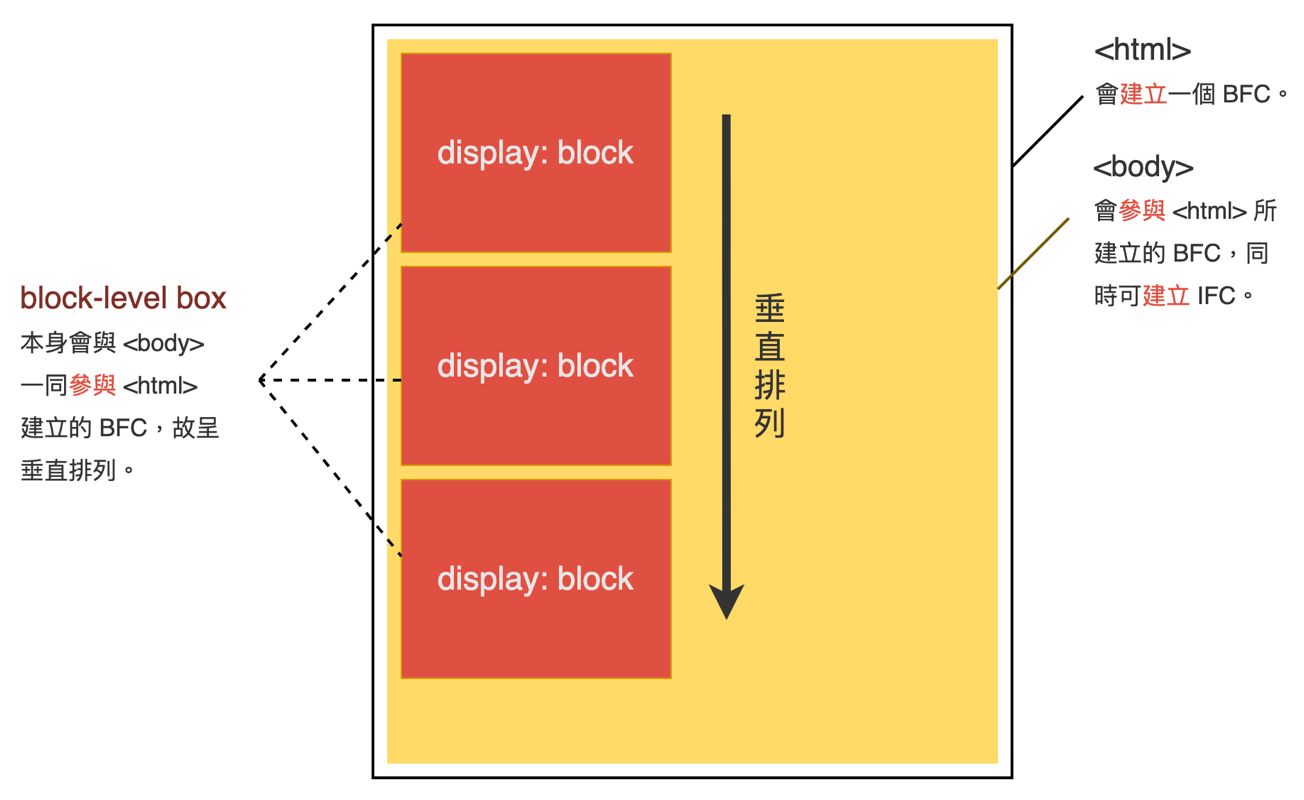
所有块级盒子都会参与 BFC,呈现垂直排列;而所有行内级盒子都参会 IFC,呈现水平排列。
block 占满一行,默认继承父元素的宽度;多个块元素将从上到下进行排列;
inline 不会占满一行,宽度随着内容而变化;多个 inline 元素将按照从左到右的顺序在一行里排列显示,如果一行显示不下,则自动换行;
inline-block 是行内块元素,不单独占满一行,可以看成是能够在一行里进行左右排列的块元素;
inner display type 对内方面,其实就是把元素当成了容器,里面包裹着文本或者其他子元素。container box 的类型依据 display 的值不同,分为 4 种:
block container:建立BFC 或者 IFC;
值得⼀提的是如果把 img 这种替换元素(replaced element)申明为 block 是不会产生container box 的,因为替换元素比如 img 设计的初衷就仅仅是通过 src 把内容替换成图片,完全没考虑过会把它当成容器。
格式化上下文 格式化上下文(Formatting Context)说的是页面中一块渲染区域,规定了渲染区域内部的子元素是如何排版以及相互作用的。
不同的盒子有不同的格式化上下文,大概有四类:
BFC (Block Formatting Context) 块级格式化上下文;
BFC和IFC扮演着非常重要的角色,因为它们直接影响了网页布局。
BFC 块格式化上下文,是一个独立的渲染区域,只有块级盒子参与,规定了内部的块级盒子如何布局,并且与这个区域外部毫不相干。
BFC渲染规则 内部的盒子会在垂直方向,一个接一个地放置;
如何创建BFC 根元素:html
BFC应用场景
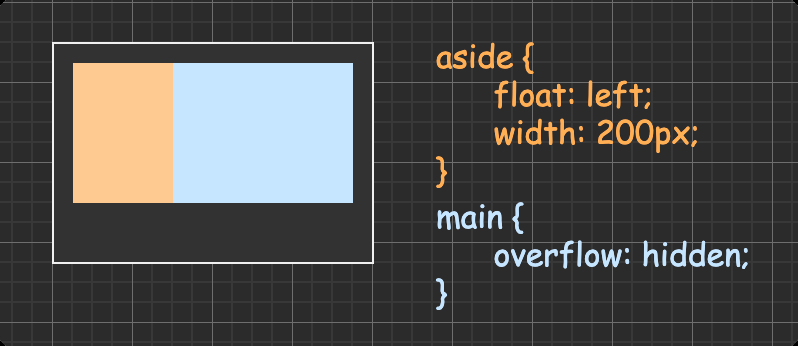
自适应两栏布局
应用原理:BFC 的区域不会和浮动区域重叠,所以就可以把侧边栏固定宽度且左浮动,而对右侧内容触发 BFC,使得它的宽度自适应该行剩余宽度。
1 2 3 4 <div class ="layout" > <div class ="aside" > aside</div > <div class ="main" > main</div > </div >
1 2 3 4 5 6 7 8 .aside { float : left; width : 100px ; } .main { <!-- 触发 BFC --> overflow : auto; }
清除内部浮动
浮动造成的问题就是父元素高度坍塌,所以清除浮动需要解决的问题就是让父元素的高度恢复正常。而用BFC 清除浮动的原理就是:计算 BFC 的高度时,浮动元素也参与计算。只要触发父元素的 BFC 即可。
1 2 3 .parent { overflow : hidden; }
防止垂直margin合并
BFC 渲染原理之一:同一个 BFC 下的垂直 margin 会发生合并。所以如果让 2 个元素不在同一个BFC 中即可阻质止垂直 margin 合并。那如何让 2 个相邻的兄弟元素不在同⼀个 BFC 中呢?可以给其中一个元素外面包裹一层,然后触发其包裹层的 BFC,这样一来 2 个元素就不会在同一个 BFC中了。
1 2 3 4 5 6 <div class ="layout" > <div class ="a" > a</div > <div class ="contain-b" > <div class ="b" > b</div > </div > </div >
1 2 3 4 5 6 7 8 .demo3 .a ,.demo3 .b { border : 1px solid #999 ; margin : 10px ; } .contain-b { overflow : hidden; }
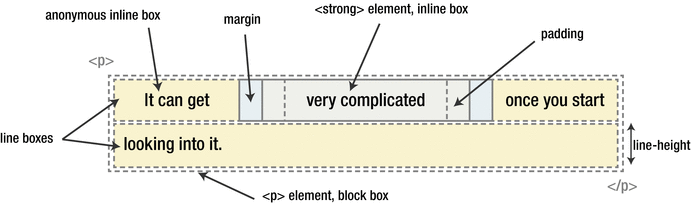
IFC IFC 的形成条件非常简单,块级元素中仅包含内联级别元素,需要注意的是当IFC中有块级元素插入时,会产生两个匿名块将父元素分割开来,产生两个 IFC。
IFC渲染规则 子元素在水平方向上一个接一个排列,在垂直方向上将以容器顶部开始向下排列;
1 <p > It can get <strong > very complicated</storng > once you start looking into it.</p >
p 标签是一个 block container,对内将产生一个 IFC;
IFC应用场景 水平居中:当一个块要在环境中水平居中时,设置其为 inline-block 则会在外层产生IFC,通过 text-align 则可以使其水平居中。
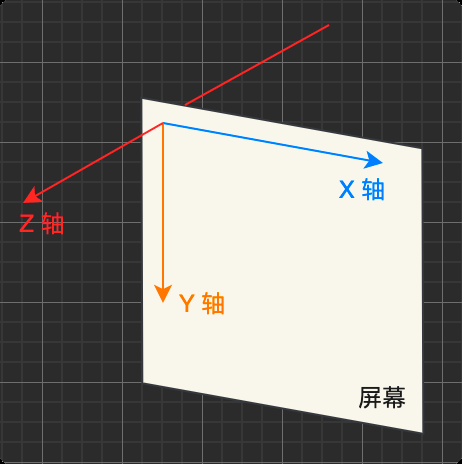
层叠上下文 屏幕上水平是X轴,垂直是Y轴,屏幕到眼睛的方向是Z轴。元素根据属性的优先级在Z轴上排开。
z-index 能够在层叠上下文中对元素的堆叠顺序其作用是必须配合定位才可以;
特定的 HTML 元素或者CSS 属性产生层叠上下文,符合以下任一条件的元素都会产生层
html ⽂档根元素
层叠等级 层叠等级指节点在三维空间Z轴上的上下顺序。
在同⼀个层叠上下文中,它描述定义的是该层叠上下文中的层叠上下文元素在 Z 轴上的上下顺序;
普通元素的层叠等级由其所在的层叠上下文决定,层叠等级的比较只有在当前层叠上下文中才有意义,脱离当前层叠上下文的比较就无意义了。
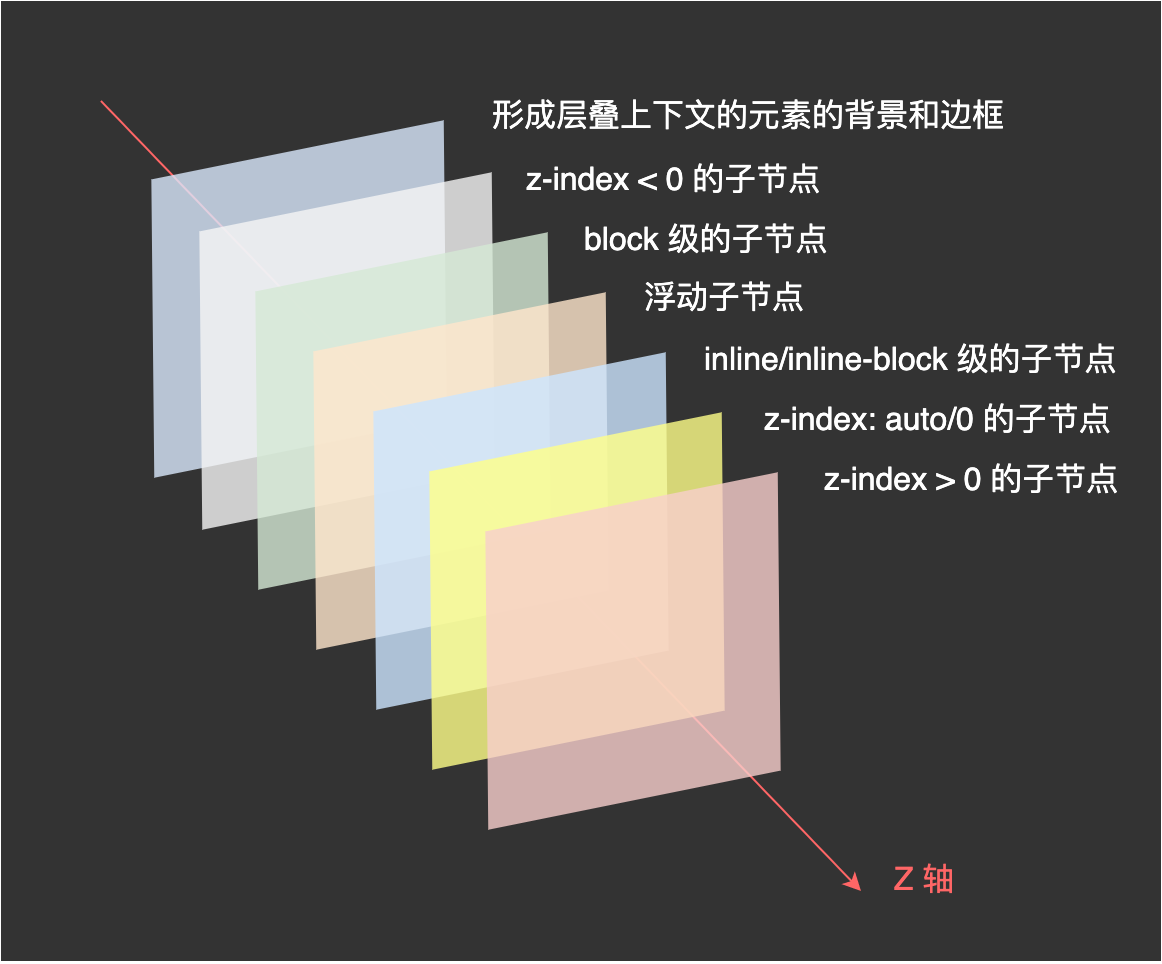
层叠顺序 同一个层叠上下文如果有多个元素,它们之前的层叠顺序。
层叠等级由低到高:
层叠上下文的 border 和 background
如何比较两个元素的层叠等级? 在同一个层叠上下文中,比较两个元素就是按照上图的介绍的层叠顺序进行比较。
值和单位 数值:长度值 ,用于指定例如元素 width、border-width、font-size 等属性的值;
还有些值是需要带单位的,比如 width: 100px,这里的 px 就是表示长度的单位,长度单位除了px 外,比较常用的还有 em、rem、vw/vh 等。
px 屏幕分辨率是指在屏幕的横纵方向上的像素点数量,比如分辨率 1920×1080 意味着水平方向含有1920 个像素数,垂直方向含有 1080 个像素数。
屏幕尺寸一致的情况下,屏幕分辨率越高,显示效果就越细腻。
em em 是 CSS 中的相对长度单位中的一个。
在 font-size 中使用是相对于父元素的 font-size 大小,比如父元素 font-size: 16px,当给子元素指定 font-size: 2em 的时候,经过计算后它的字体大小会是 32px;
每个浏览器都会给 HTML 根元素 html 设置一个默认的 font-size,而这个值通常是16px。这也就是为什么 1em = 16px 的原因所在了。
rem rem(root em) 和 em一样,也是一个相对长度单位,不过 rem 相对的是 HTML 的根元素html。
rem 由于是基于 html 的 font-size 来计算,所以通常用于自适应网站或者 H5 中。
vw/vh vw 和 vh 分别是相对于屏幕视口宽度和高度而言的长度单位:
相对视口的单位,除了 vw/vh 外,还有 vmin 和 vmax:
vmin:取 vw 和 vh 中值较小的;
vmax:取 vw 和 vh 中值较大的;
颜色体系 根据 CSS 颜色草案 中提到的颜色值类型,大概可以把它们分为这几类:
颜色关键字
transparent 关键字
currentColor 关键字
RGB 颜色
HSL 颜色
颜色关键字 颜色关键字(color keywords)是不区分大小写的标识符,它表示一个具体的颜色,比如 white(白),黑(black)等;
transparent关键字 transparent 关键字表示⼀个完全透明的颜色,即该颜色看上去将是背景色。
应用场景:
实现三角形 等腰三角形:设置⼀条边有颜色,然后紧挨着的 2 边是透明,且宽度是有颜色边的⼀半;直角三角形:设置⼀条边有颜色,然后紧挨着的任何一边透明即可。
增大点击区域 常常在移动端的时候点击的按钮的区域特别小,但是由于现实效果又不太好把它做大,所以常用的⼀个手段就是通过透明的边框来增大按钮的点击区域
currentColor关键字 currentColor 会取当前元素继承父级元素的文本颜色值或声明的文本颜色值,即 computed 后的color 值。
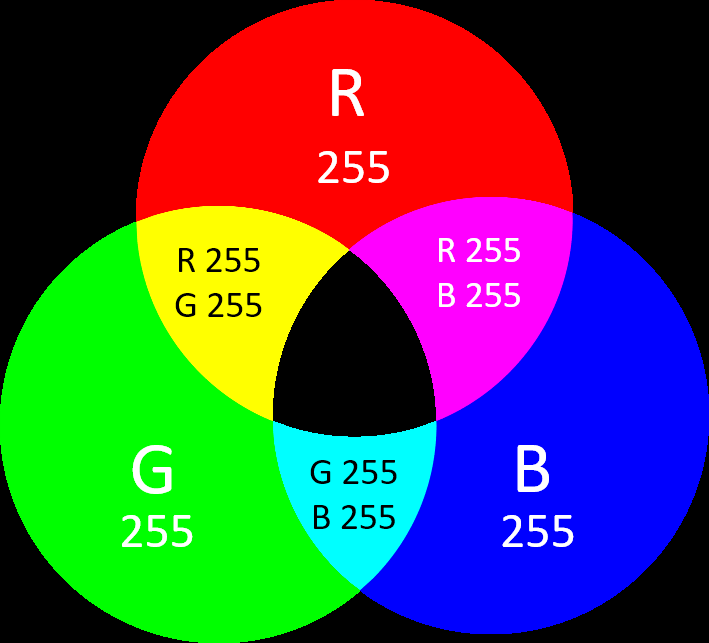
RGB[A]颜色 RGB[A] 颜色是由 R(red)-G(green)-B(blue)-A(alpha) 组成的色彩空间。
十六进制符号 RGB 中的每种颜色的值范围是 00~ff,值越大表示颜色越深。所以⼀个颜色正常是 6 个十六进制字符加上 # 组成,比如红色就是 #ff0000。
如果 RGB 颜⾊需要加上不透明度,那就需要加上 alpha 通道的值,它的范围也是 00~ff,比如一个带不透明度为 67% 的红色可以这样写 #ff0000aa。
使用十六进制符号表示颜色的时候,都是用 2 个十六进制表示一个颜色,如果这 2 个字符相同,还可以缩减成只写 1 个,比如,红色 #f00;带 67% 不透明度的红色 #f00a。
函数符 当 RGB 用函数表示的时候,每个值的范围是 0255 或者 0%100%,所以红色是 rgb(255, 0,0), 或者 rgb(100%, 0, 0)。1 及其之间的小数或者0%100%,比如带 67% 不透明度的红色是 rgba(255, 0, 0, 0.67) 或者 rgba(100%, 0%, 0%, 67%)
要么都用数字,要么都用百分比,同时用是不对的,但是透明度不需要保持一致。rgb(100%, 0%, 0%, 0.67)
带 67% 不透明度的红色可以这样写 rgba(255 0 0 / 0.67)
HSL[A]颜色 HSL[A] 颜色是由色相(hue)-饱和度(saturation)-亮度(lightness)-不透明度组成的颜色体系。100% 的数值;0% 为灰色, 100% 全色;100%,0% 为暗,100% 为白;
在 Chrome DevTools 中可以按住 shift + 鼠标左键可以切换颜色的表示方式。
媒体查询 媒体查询是指针对不同的设备、特定的设备特征或者参数进行定制化的修改网站的样式。
给
1 2 <link rel ="stylesheet" src ="styles.css" media ="screen" /> <link rel ="stylesheet" src ="styles.css" media ="print" />
all:适用于所有设备;
除了通过
1 @media (min-width : 1000px ) {}
媒体查询支持逻辑操作符:
1 2 @media (min-height : 680px ), screen and (orientation : portrait) {}
常见需求 自定义属性 现在 CSS 里也支持了变量的用法。通过自定义属性就可以在想要使用的地方引用它。
自定义属性也和普通属性一样具有级联性,申明在 :root 下的时候,在全文档范围内可用,而如果是在某个元素下申明自定义属性,则只能在它及它的子元素下才可以使用。
自定义属性必须通过 –x 的格式申明,比如:–theme-color: red; 使用自定义属性的时候,需要用 var 函数。比如:
1 2 3 4 5 6 7 8 <!-- 定义⾃定义属性 --> :root { --theme-color : red; } <!-- 使⽤变量 --> h1 { color : var (--theme-color); }
1px边框实现方案 Retina 显示屏比普通的屏幕有着更高的分辨率,所以在移动端的 1px 边框就会看起比较粗,为了美观通常需要把这个线条细化处理。
只设置单条底部边框:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 .scale-1px-bottom { position : relative; border :none; } .scale-1px-bottom ::after { content : '' ; position : absolute; left : 0 ; bottom : 0 ; background : #000 ; width : 100% ; height : 1px ; -webkit-transform : scaleY (0.5 ); transform : scaleY (0.5 ); -webkit-transform-origin : 0 0 ; transform-origin : 0 0 ; }
同时设置 4 条边框:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 .scale-1px { position : relative; margin-bottom : 20px ; border :none; } .scale-1px ::after { content : '' ; position : absolute; top : 0 ; left : 0 ; border : 1px solid #000 ; -webkit-box-sizing : border-box; box-sizing : border-box; width : 200% ; height : 200% ; -webkit-transform : scale (0.5 ); transform : scale (0.5 ); -webkit-transform-origin : left top; transform-origin : left top; }
清除浮动 浮动:浮动元素会脱离文档流并向左/向右浮动,直到碰到父元素或者另⼀个浮动元素。
为什么要清除浮动:
因为浮动元素会脱离正常的文档流,并不会占据文档流的位置,所以如果⼀个父元素下面都是浮动元素,那么这个父元素就无法被浮动元素所撑开,这样⼀来父元素就丢失了高度,这就是所谓的浮动造成的父元素高度坍塌问题。
父元素高度一旦坍塌将对后面的元素布局造成影响。
两种方法:通过 BFC 来清除、通过 clear 来清除。
BFC清除浮动 前面介绍 BFC 的时候提到过,计算 BFC 高度的时候浮动子元素的高度也将计算在内,利用这条规则就可以清除浮动。
假设⼀个父元素 parent 内部只有 2 个子元素 child,且它们都是左浮动的,这个时候 parent 如果没有设置高度的话,因为浮动造成了高度坍塌,所以 parent 的高度会是 0,此时只要给 parent创造⼀个 BFC,那它的高度就能恢复了。
而产生BFC 的方式很多,我们可以给父元素设置overflow: auto 来简单的实现 BFC 清除浮动,但是为了兼容 IE 最好用overflow: hidden。
1 2 3 .parent { overflow : hidden; }
通过 overflow: hidden 来清除浮动并不完美,当元素有阴影或存在下拉菜单的时候会被截断,所以该方法使用比较局限。
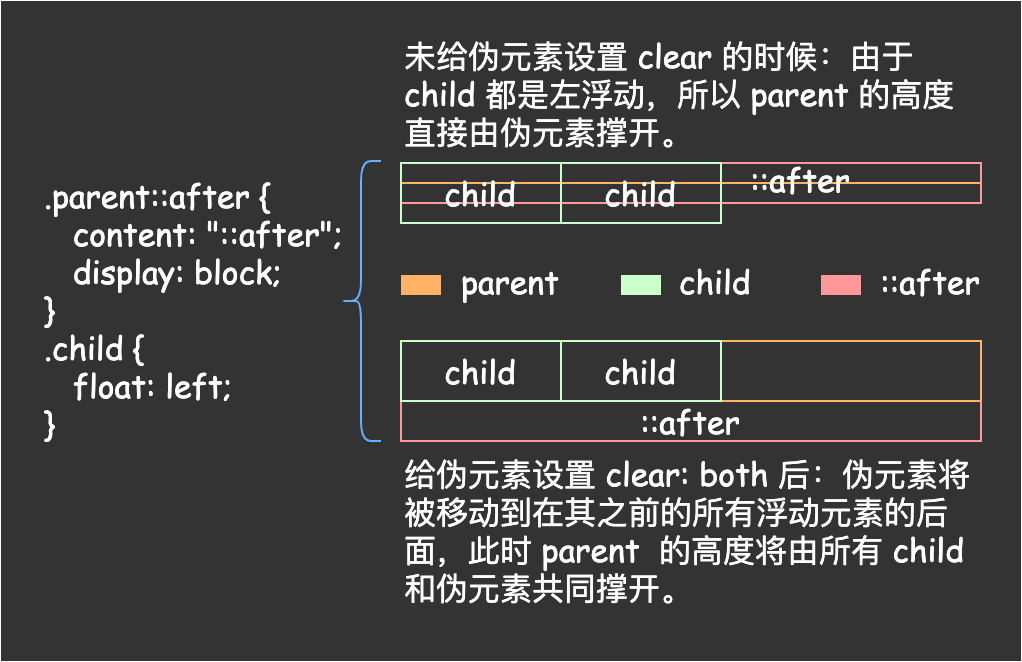
通过clear清除浮动 1 2 3 4 5 6 7 8 .clearfix { zoom: 1 ; } .clearfix ::after { content : "" ; display : block; clear : both; }
这种写法的核心原理就是通过 ::after 伪元素为在父元素的最后一子元素后面生成一个内容为空的块级元素,然后通过 clear 将这个伪元素移动到所有它之前的浮动元素的后面,画个图来理解一下。
上面这个 demo 或者图里为了展示需要所以给伪元素的内容设置为了 ::after,实际使用的时候需要设置为空字符串,让它的高度为 0,从而父元素的高度都是由实际的子元素撑开。
消除浏览器默认样式 针对同⼀个类型的 HTML 标签,不同的浏览器往往有不同的表现,所以在网站制作的时候,开发者通常都是需要将这些浏览器的默认样式清除,让网页在不同的浏览器上能够保持一致。
reset.css,Normalize.css
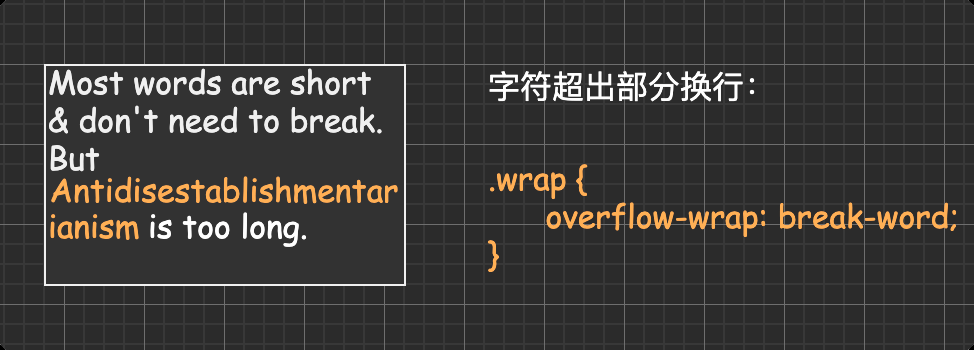
长文本处理 默认:字符太长溢出了容器
字符超出部分换行
字符超出位置使用连字符
单行文本超出省略
多行文本超出省略
水平垂直居中 让元素在父元素中呈现水平垂直居中的几种情况:
单行的文本、inline 或者 inline-block 元素;
单行的文本、inline或inline-block元素 水平居中 此类元素需要水平居中,则父级元素必须是块级元素( block level ),且父级元素上需要这样设置样式:
1 2 3 .parent { text-align : center; }
垂直居中 方法一:通过设置上下内间距一致达到垂直居中的效果:
1 2 3 4 .single-line { padding-top : 10px ; padding-bottom : 10px ; }
方法二:通过设置 height 和 line-height 一致达到垂直居中:
1 2 3 4 .single-line { height : 100px ; line-height : 100px ; }
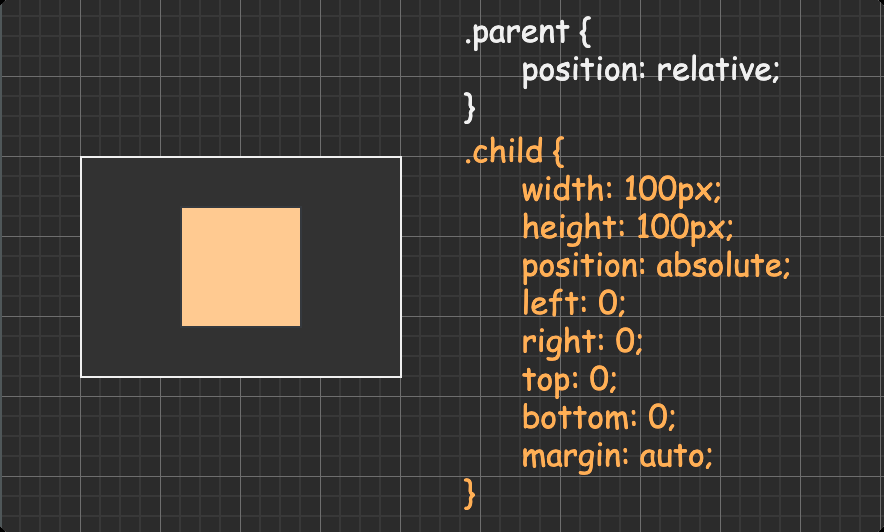
固定宽高的块级盒子 方法一:absolute + 负 margin
方法二:absolute + margin auto
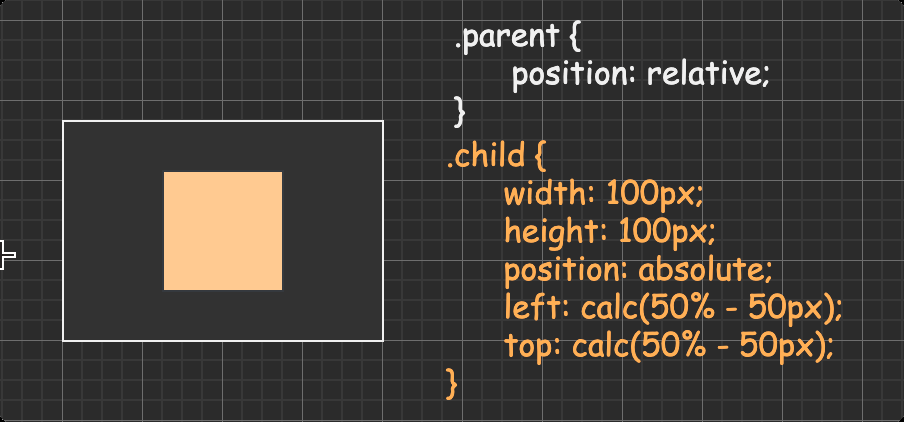
方法三:absolute + calc
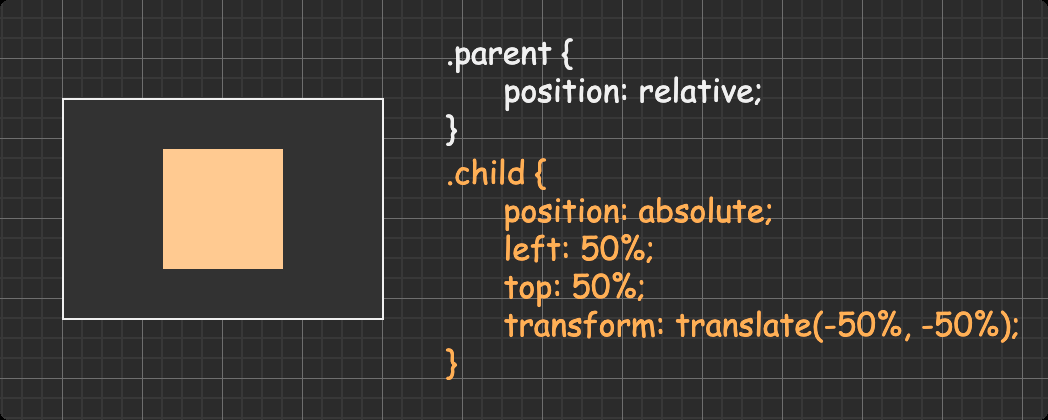
不固定宽高的块级盒子 方法一:absolute + transform
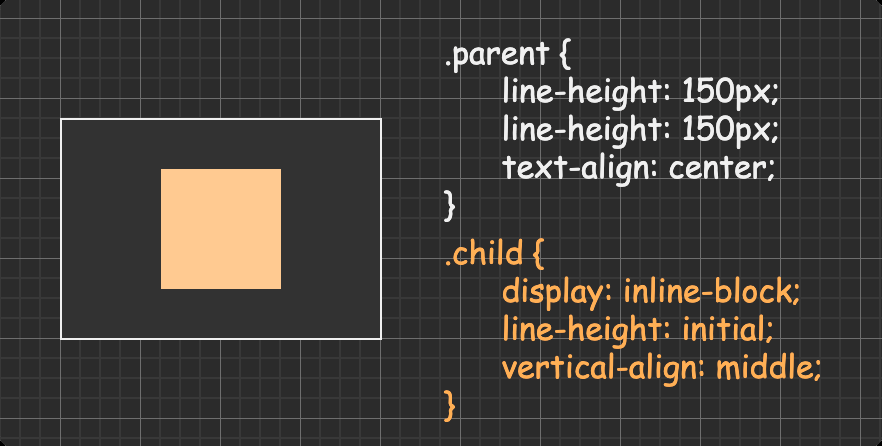
方法二:line-height + vertical-align
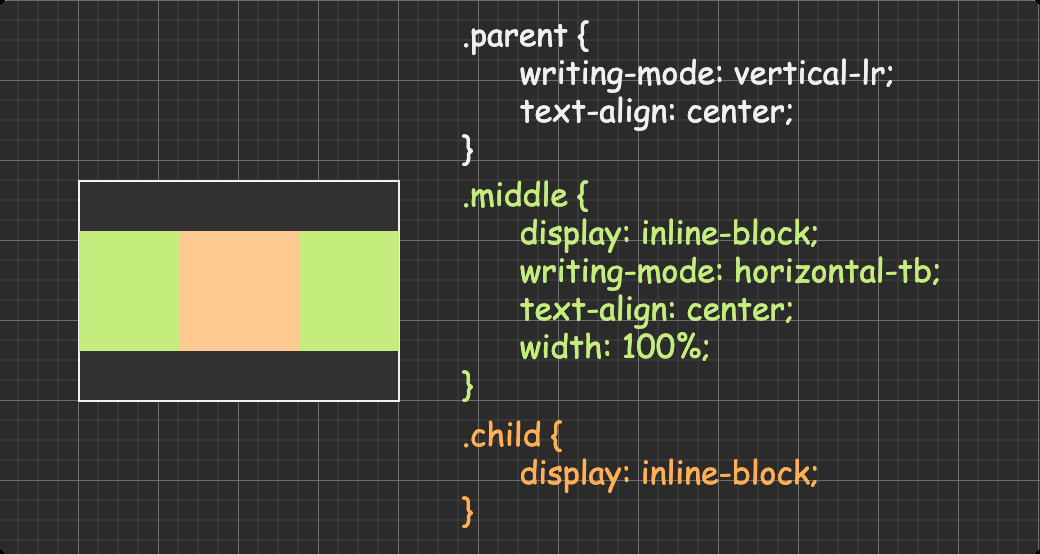
方法三:writing-mode
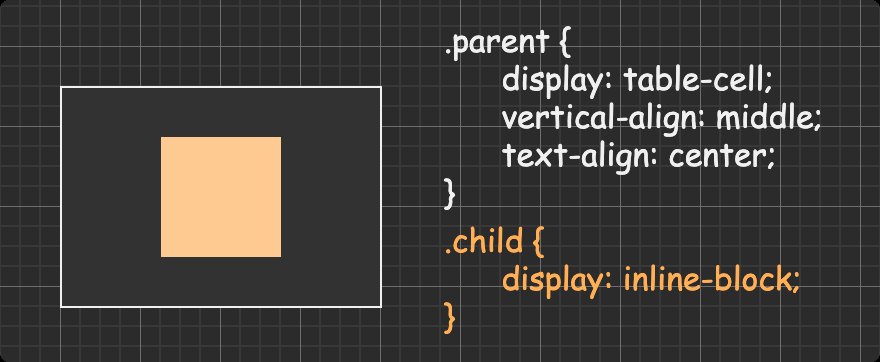
方法四:table-cell
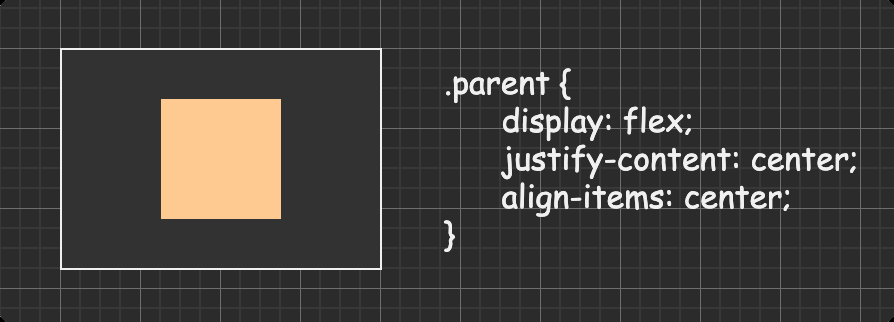
方法五:flex
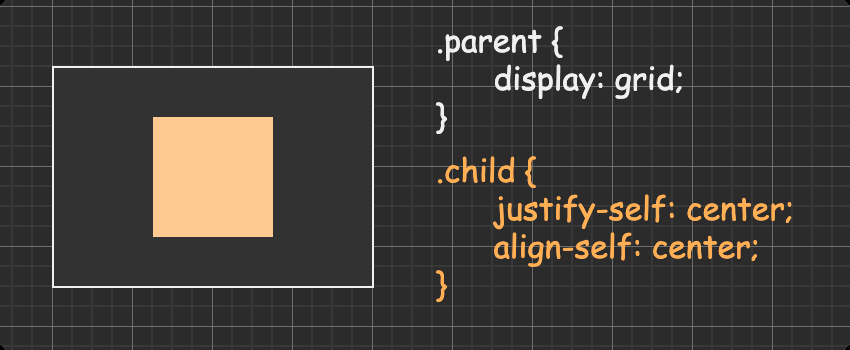
方法六:grid
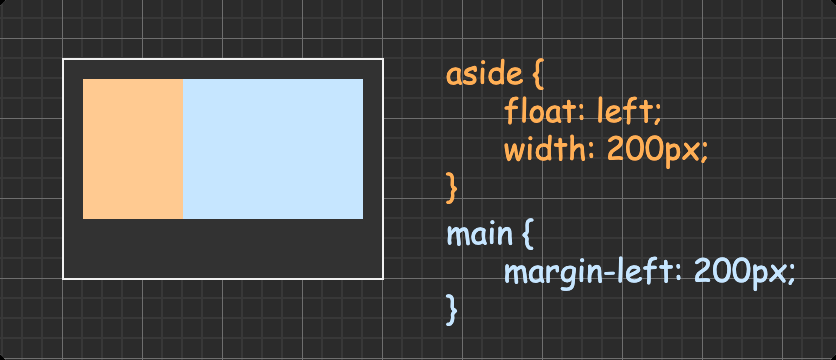
常用布局 两栏布局(边栏定宽主栏自适应) 方法一:float + overflow(BFC 原理)
方法二:float + margin
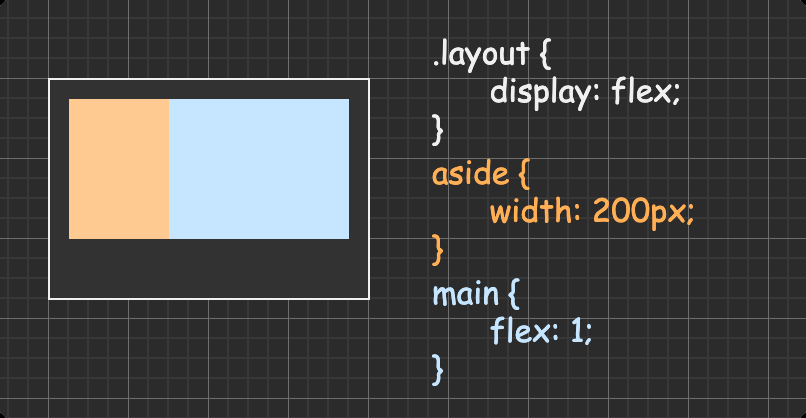
方法三:flex
方法四:grid
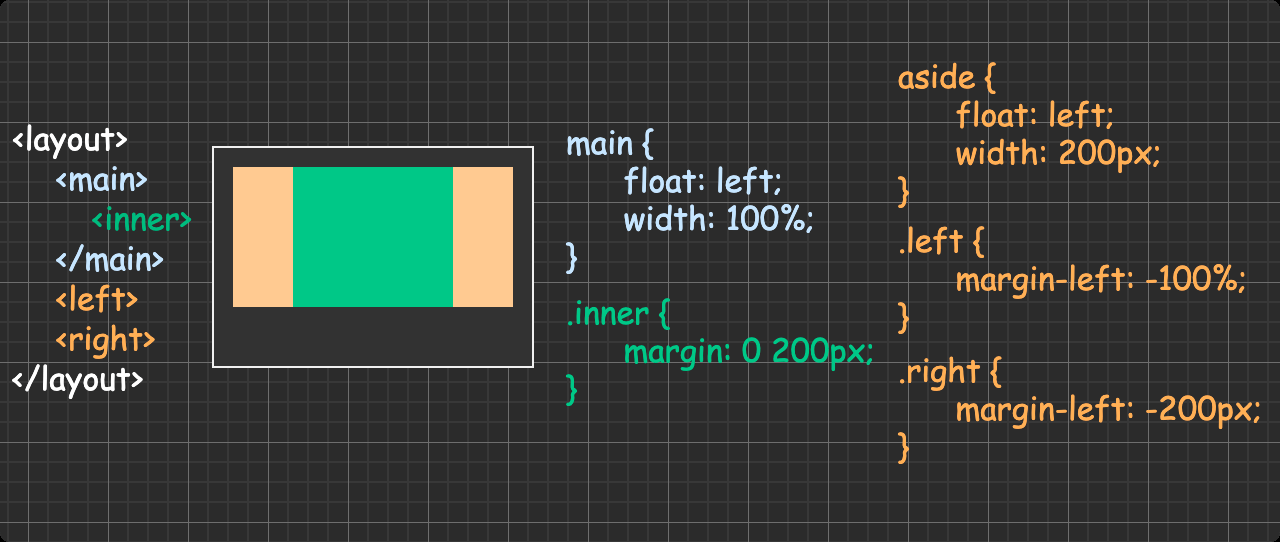
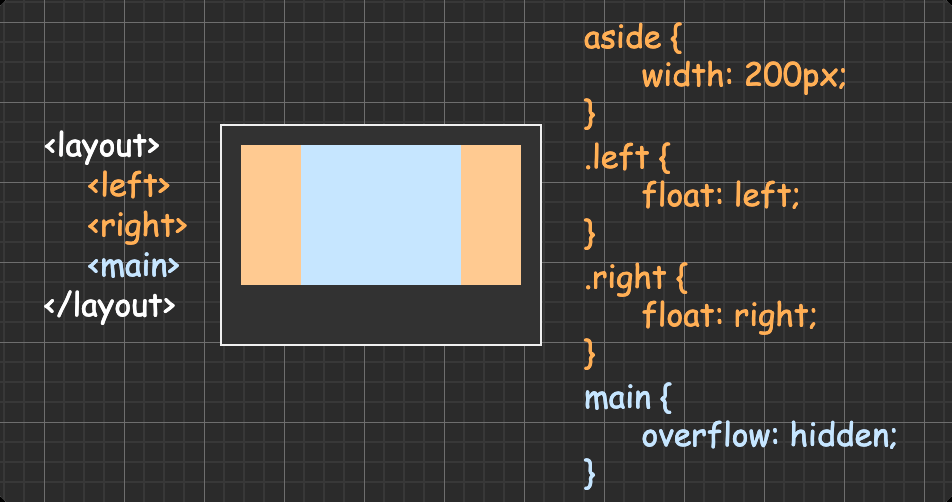
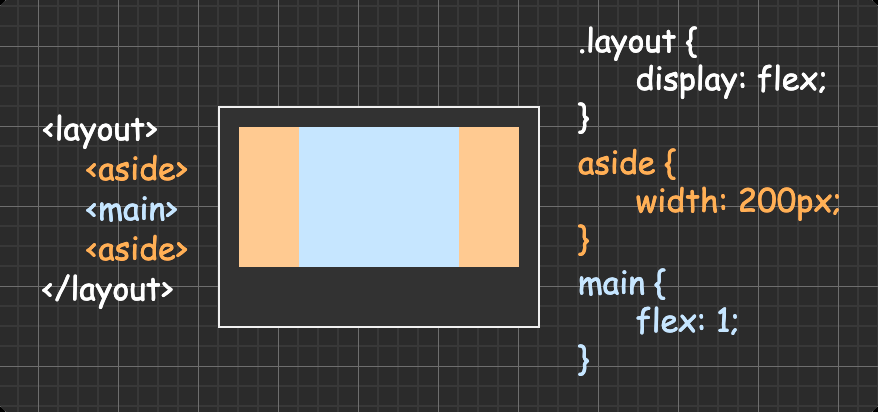
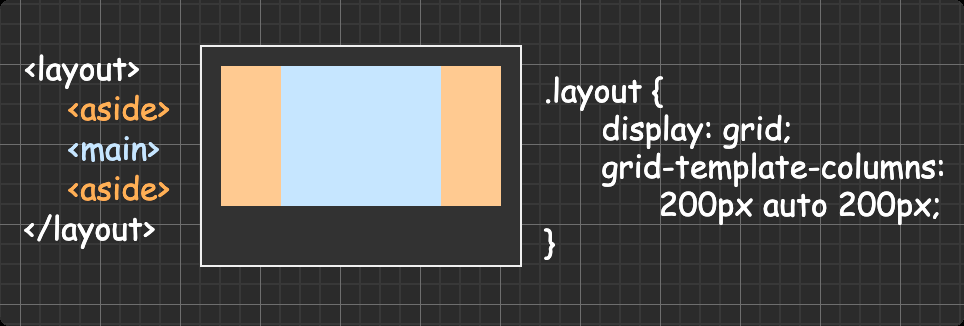
三栏布局(两侧栏定宽主栏自适应) 方法一:圣杯布局
方法二:双飞翼布局
方法三:float + overflow(BFC 原理)
方法四:flex
方法五:grid
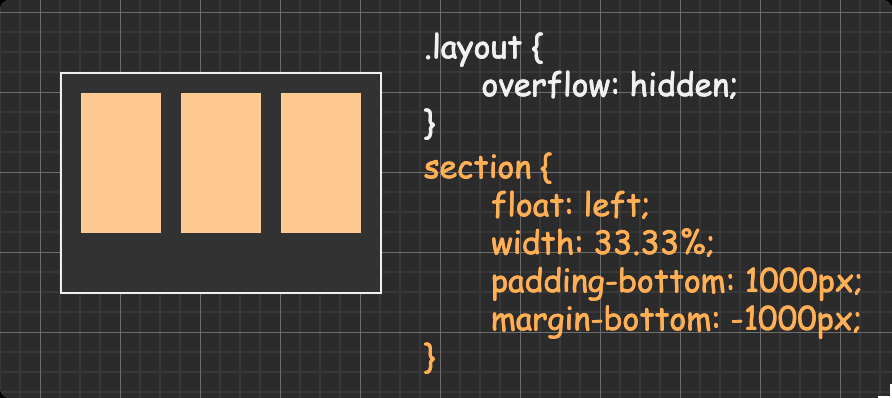
多列等高布局 方法一:padding + 负margin
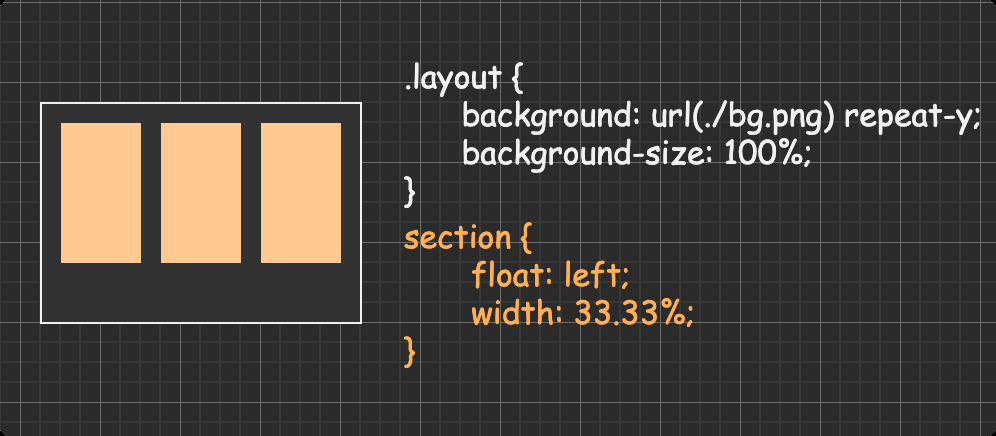
方法二:设置父级背景图片
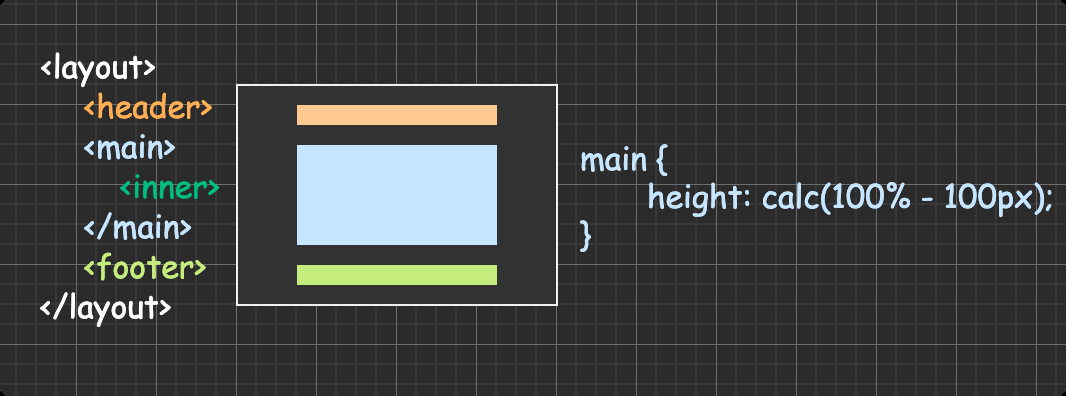
三行布局(头尾定高主栏自适应) 1 2 3 4 5 6 7 <div class ="layout" > <header > </header > <main > <div class ="inner" > </div > </main > <footer > </footer > </div >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 html ,body ,.layout { height : 100% ; } body { margin : 0 ; } header ,footer { height : 50px ; } main { overflow-y : auto; }
方法一:calc
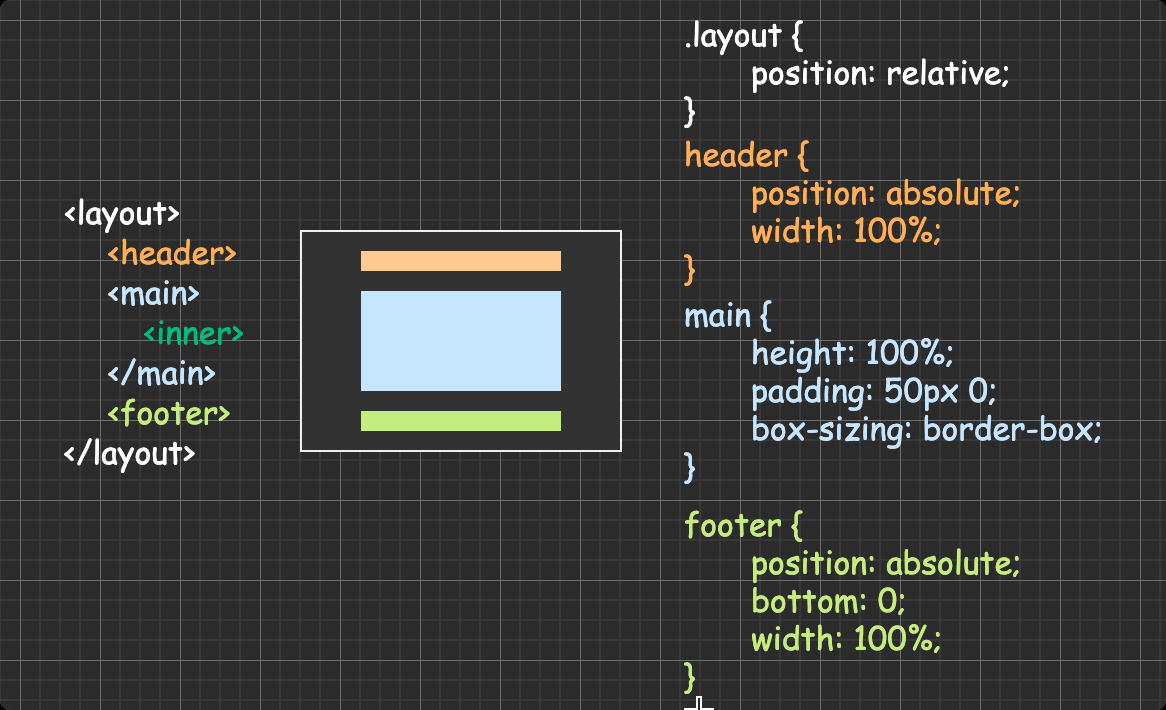
方法二:absolute
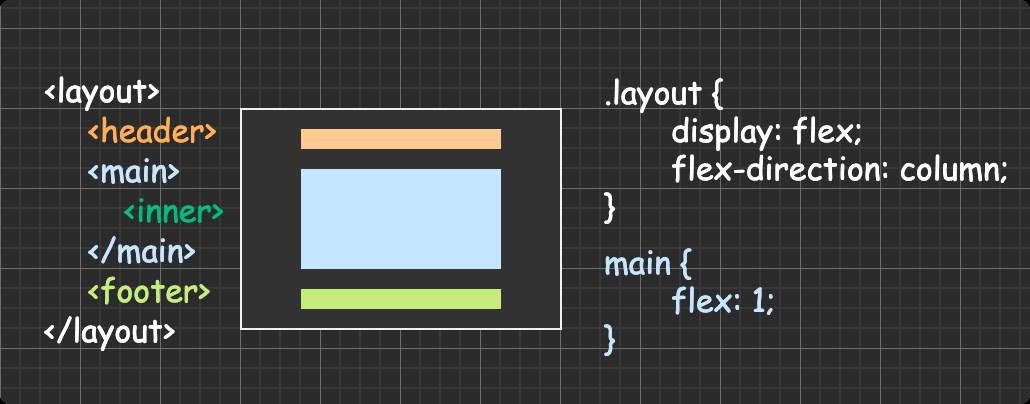
方法三:flex
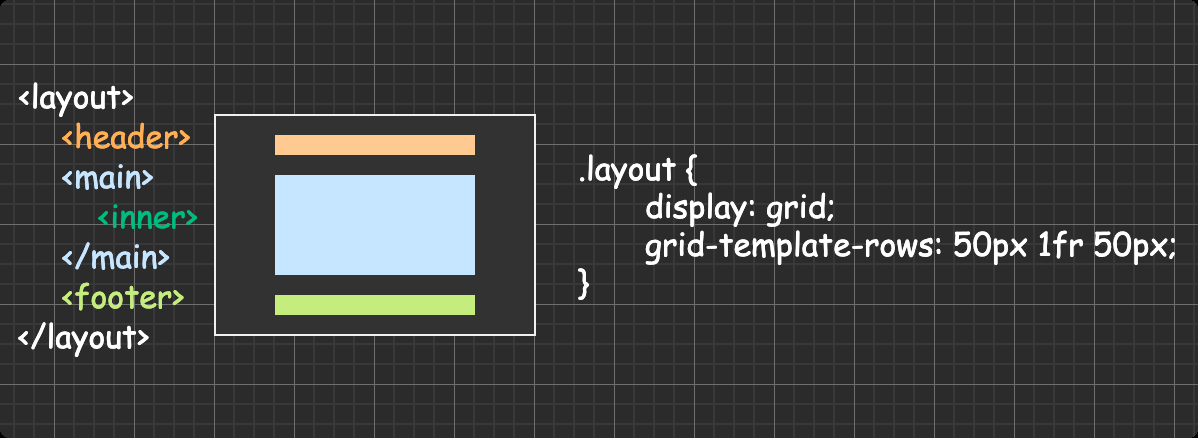
方法四:grid